🎯 上下文工程(Context Engineering)
掌握构建可靠 AI Agent 的核心技术——通过提供正确的信息和工具, 使 LLM 能够准确完成任务。这是 AI 工程师的首要职责。
概述
构建 Agent(或任何 LLM 应用)最困难的部分是让它们足够可靠。 虽然它们在原型阶段可能有效,但在实际使用案例中经常失败。
为什么 Agent 会失败?
当 Agent 失败时,通常是因为 Agent 内部的 LLM 调用采取了错误的行动, 或者没有按照我们的期望执行。LLM 失败通常有两个原因:
- 底层 LLM 能力不足
- "正确"的上下文未传递给 LLM
更多情况下,实际上是第二个原因导致 Agent 不可靠。
上下文工程是以正确的格式提供正确的信息和工具, 使 LLM 能够完成任务。这是 AI 工程师的首要工作。 缺乏"正确"的上下文是阻碍更可靠 Agent 的首要障碍, LangChain 的 Agent 抽象专门设计用于促进上下文工程。
Agent 循环
典型的 Agent 循环包含两个主要步骤:
- 模型调用 - 使用提示词和可用工具调用 LLM,返回响应或工具执行请求
- 工具执行 - 执行 LLM 请求的工具,返回工具结果
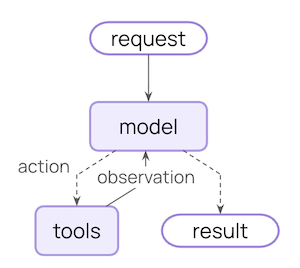
这个循环会持续进行,直到 LLM 决定完成。
可控制的内容
要构建可靠的 Agent,您需要控制 Agent 循环每一步发生的事情, 以及步骤之间发生的事情。
| 上下文类型 | 可控制的内容 | 瞬态或持久 |
|---|---|---|
| 模型上下文 | 进入模型调用的内容(指令、消息历史、工具、响应格式) | 瞬态 |
| 工具上下文 | 工具可以访问和产生的内容(读/写状态、存储、运行时上下文) | 持久 |
| 生命周期上下文 | 模型和工具调用之间发生的事情(摘要、防护栏、日志等) | 持久 |
- 瞬态上下文:LLM 在单次调用中看到的内容。 您可以修改消息、工具或提示词,而不改变状态中保存的内容。
- 持久上下文:跨轮次保存在状态中的内容。 生命周期钩子和工具写入会永久修改它。
数据源
在整个过程中,您的 Agent 访问(读/写)不同的数据源:
| 数据源 | 也称为 | 范围 | 示例 |
|---|---|---|---|
| Runtime Context | 静态配置 | 会话范围 | 用户 ID、API 密钥、数据库连接、权限、环境设置 |
| State | 短期记忆 | 会话范围 | 当前消息、上传文件、认证状态、工具结果 |
| Store | 长期记忆 | 跨会话 | 用户偏好、提取的见解、记忆、历史数据 |
工作原理
LangChain 中间件(Middleware)是使上下文工程对使用 LangChain 的开发者变得实用的底层机制。
中间件允许您连接到 Agent 生命周期的任何步骤,并且:
- 更新上下文
- 跳转到 Agent 生命周期的不同步骤
在本指南中,您将经常看到使用中间件 API 作为实现上下文工程目标的手段。
模型上下文(Model Context)
控制进入每次模型调用的内容——指令、可用工具、使用哪个模型以及输出格式。 这些决策直接影响可靠性和成本。
系统提示词(System Prompt)
系统提示词设置 LLM 的行为和能力。不同的用户、上下文或对话阶段需要不同的指令。 成功的 Agent 会利用记忆、偏好和配置为当前对话状态提供正确的指令。
从 State 读取
from langchain.agents import create_agent
from langchain.agents.middleware import dynamic_prompt, ModelRequest
@dynamic_prompt
def state_aware_prompt(request: ModelRequest) -> str:
# request.messages 是 request.state["messages"] 的快捷方式
message_count = len(request.messages)
base = "You are a helpful assistant."
if message_count > 10:
base += "\nThis is a long conversation - be extra concise."
return base
agent = create_agent(
model="gpt-4o",
tools=[...],
middleware=[state_aware_prompt]
)从 Store 读取
from dataclasses import dataclass
from langchain.agents import create_agent
from langchain.agents.middleware import dynamic_prompt, ModelRequest
from langgraph.store.memory import InMemoryStore
@dataclass
class Context:
user_id: str
@dynamic_prompt
def store_aware_prompt(request: ModelRequest) -> str:
user_id = request.runtime.context.user_id
# 从 Store 读取:获取用户偏好
store = request.runtime.store
user_prefs = store.get(("preferences",), user_id)
base = "You are a helpful assistant."
if user_prefs:
style = user_prefs.value.get("communication_style", "balanced")
base += f"\nUser prefers {style} responses."
return base
agent = create_agent(
model="gpt-4o",
tools=[...],
middleware=[store_aware_prompt],
context_schema=Context,
store=InMemoryStore()
)从 Runtime Context 读取
from dataclasses import dataclass
from langchain.agents import create_agent
from langchain.agents.middleware import dynamic_prompt, ModelRequest
@dataclass
class Context:
user_role: str
deployment_env: str
@dynamic_prompt
def context_aware_prompt(request: ModelRequest) -> str:
# 从 Runtime Context 读取:用户角色和环境
user_role = request.runtime.context.user_role
env = request.runtime.context.deployment_env
base = "You are a helpful assistant."
if user_role == "admin":
base += "\nYou have admin access. You can perform all operations."
elif user_role == "viewer":
base += "\nYou have read-only access. Guide users to read operations only."
if env == "production":
base += "\nBe extra careful with any data modifications."
return base
agent = create_agent(
model="gpt-4o",
tools=[...],
middleware=[context_aware_prompt],
context_schema=Context
)消息(Messages)
消息构成发送给 LLM 的提示词。管理消息内容对于确保 LLM 拥有正确的信息以良好响应至关重要。
从 State 注入文件上下文
from langchain.agents import create_agent
from langchain.agents.middleware import wrap_model_call, ModelRequest, ModelResponse
from typing import Callable
@wrap_model_call
def inject_file_context(
request: ModelRequest,
handler: Callable[[ModelRequest], ModelResponse]
) -> ModelResponse:
"""注入用户在此会话中上传的文件上下文"""
# 从 State 读取:获取上传的文件元数据
uploaded_files = request.state.get("uploaded_files", [])
if uploaded_files:
# 构建可用文件的上下文
file_descriptions = []
for file in uploaded_files:
file_descriptions.append(
f"- {file['name']} ({file['type']}): {file['summary']}"
)
file_context = f"""Files you have access to in this conversation:
{chr(10).join(file_descriptions)}
Reference these files when answering questions."""
# 在最近的消息之前注入文件上下文
messages = [
*request.messages,
{"role": "user", "content": file_context},
]
request = request.override(messages=messages)
return handler(request)
agent = create_agent(
model="gpt-4o",
tools=[...],
middleware=[inject_file_context]
)
上述示例使用 wrap_model_call 进行瞬态更新——
修改单次调用发送给模型的消息,而不改变状态中保存的内容。
对于修改状态的持久更新(如生命周期上下文中的摘要示例),
使用生命周期钩子如 before_model 或 after_model
来永久更新对话历史。
工具(Tools)
工具让模型与数据库、API 和外部系统交互。您定义和选择工具的方式直接影响模型能否有效完成任务。
定义工具
每个工具都需要清晰的名称、描述、参数名称和参数描述。 这些不仅仅是元数据——它们指导模型何时以及如何使用工具。
from langchain.tools import tool
@tool(parse_docstring=True)
def search_orders(
user_id: str,
status: str,
limit: int = 10
) -> str:
"""Search for user orders by status.
Use this when the user asks about order history or wants to check
order status. Always filter by the provided status.
Args:
user_id: Unique identifier for the user
status: Order status: 'pending', 'shipped', or 'delivered'
limit: Maximum number of results to return
"""
# Implementation here
pass动态选择工具
并非每个工具都适用于每种情况。工具过多可能会让模型不堪重负(上下文过载)并增加错误; 工具过少会限制能力。动态工具选择根据认证状态、用户权限、功能标志或对话阶段调整可用工具集。
from langchain.agents import create_agent
from langchain.agents.middleware import wrap_model_call, ModelRequest, ModelResponse
from typing import Callable
@wrap_model_call
def state_based_tools(
request: ModelRequest,
handler: Callable[[ModelRequest], ModelResponse]
) -> ModelResponse:
"""基于对话 State 过滤工具"""
# 从 State 读取:检查用户是否已认证
state = request.state
is_authenticated = state.get("authenticated", False)
message_count = len(state["messages"])
# 只在认证后启用敏感工具
if not is_authenticated:
tools = [t for t in request.tools if t.name.startswith("public_")]
request = request.override(tools=tools)
elif message_count < 5:
# 在对话早期限制工具
tools = [t for t in request.tools if t.name != "advanced_search"]
request = request.override(tools=tools)
return handler(request)
agent = create_agent(
model="gpt-4o",
tools=[public_search, private_search, advanced_search],
middleware=[state_based_tools]
)模型选择(Model)
不同的模型具有不同的优势、成本和上下文窗口。为手头的任务选择合适的模型, 这可能会在 Agent 运行期间发生变化。
from langchain.agents import create_agent
from langchain.agents.middleware import wrap_model_call, ModelRequest, ModelResponse
from langchain.chat_models import init_chat_model
from typing import Callable
# 在中间件外部初始化模型一次
large_model = init_chat_model("claude-sonnet-4-5-20250929")
standard_model = init_chat_model("gpt-4o")
efficient_model = init_chat_model("gpt-4o-mini")
@wrap_model_call
def state_based_model(
request: ModelRequest,
handler: Callable[[ModelRequest], ModelResponse]
) -> ModelResponse:
"""基于 State 对话长度选择模型"""
# request.messages 是 request.state["messages"] 的快捷方式
message_count = len(request.messages)
if message_count > 20:
# 长对话 - 使用具有更大上下文窗口的模型
model = large_model
elif message_count > 10:
# 中等对话
model = standard_model
else:
# 短对话 - 使用高效模型
model = efficient_model
request = request.override(model=model)
return handler(request)
agent = create_agent(
model="gpt-4o-mini",
tools=[...],
middleware=[state_based_model]
)响应格式(Response Format)
结构化输出将非结构化文本转换为经过验证的结构化数据。 当提取特定字段或为下游系统返回数据时,自由格式文本是不够的。
定义格式
from pydantic import BaseModel, Field
class CustomerSupportTicket(BaseModel):
"""从客户消息中提取的结构化工单信息"""
category: str = Field(
description="Issue category: 'billing', 'technical', 'account', or 'product'"
)
priority: str = Field(
description="Urgency level: 'low', 'medium', 'high', or 'critical'"
)
summary: str = Field(
description="One-sentence summary of the customer's issue"
)
customer_sentiment: str = Field(
description="Customer's emotional tone: 'frustrated', 'neutral', or 'satisfied'"
)动态选择格式
from langchain.agents import create_agent
from langchain.agents.middleware import wrap_model_call, ModelRequest, ModelResponse
from pydantic import BaseModel, Field
from typing import Callable
class SimpleResponse(BaseModel):
"""早期对话的简单响应"""
answer: str = Field(description="A brief answer")
class DetailedResponse(BaseModel):
"""已建立对话的详细响应"""
answer: str = Field(description="A detailed answer")
reasoning: str = Field(description="Explanation of reasoning")
confidence: float = Field(description="Confidence score 0-1")
@wrap_model_call
def state_based_output(
request: ModelRequest,
handler: Callable[[ModelRequest], ModelResponse]
) -> ModelResponse:
"""基于 State 选择输出格式"""
# request.messages 是 request.state["messages"] 的快捷方式
message_count = len(request.messages)
if message_count < 3:
# 早期对话 - 使用简单格式
request = request.override(response_format=SimpleResponse)
else:
# 已建立对话 - 使用详细格式
request = request.override(response_format=DetailedResponse)
return handler(request)
agent = create_agent(
model="gpt-4o",
tools=[...],
middleware=[state_based_output]
)工具上下文(Tool Context)
工具的特殊之处在于它们既读取又写入上下文。在最基本的情况下, 当工具执行时,它接收 LLM 的请求参数并返回工具消息。工具完成其工作并产生结果。
工具还可以获取模型完成任务所需的重要信息。
读取(Reads)
大多数真实世界的工具需要的不仅仅是 LLM 的参数。它们需要用户 ID 来进行数据库查询, 需要 API 密钥来访问外部服务,或需要当前会话状态来做出决策。 工具从 State、Store 和 Runtime Context 读取以访问这些信息。
from langchain.tools import tool, ToolRuntime
from langchain.agents import create_agent
@tool
def check_authentication(
runtime: ToolRuntime
) -> str:
"""检查用户是否已认证"""
# 从 State 读取:检查当前认证状态
current_state = runtime.state
is_authenticated = current_state.get("authenticated", False)
if is_authenticated:
return "User is authenticated"
else:
return "User is not authenticated"
agent = create_agent(
model="gpt-4o",
tools=[check_authentication]
)from dataclasses import dataclass
from langchain.tools import tool, ToolRuntime
from langchain.agents import create_agent
from langgraph.store.memory import InMemoryStore
@dataclass
class Context:
user_id: str
@tool
def get_preference(
preference_key: str,
runtime: ToolRuntime[Context]
) -> str:
"""从 Store 获取用户偏好"""
user_id = runtime.context.user_id
# 从 Store 读取:获取现有偏好
store = runtime.store
existing_prefs = store.get(("preferences",), user_id)
if existing_prefs:
value = existing_prefs.value.get(preference_key)
return f"{preference_key}: {value}" if value else f"No preference set for {preference_key}"
else:
return "No preferences found"
agent = create_agent(
model="gpt-4o",
tools=[get_preference],
context_schema=Context,
store=InMemoryStore()
)from dataclasses import dataclass
from langchain.tools import tool, ToolRuntime
from langchain.agents import create_agent
@dataclass
class Context:
user_id: str
api_key: str
db_connection: str
@tool
def fetch_user_data(
query: str,
runtime: ToolRuntime[Context]
) -> str:
"""使用 Runtime Context 配置获取数据"""
# 从 Runtime Context 读取:获取 API 密钥和数据库连接
user_id = runtime.context.user_id
api_key = runtime.context.api_key
db_connection = runtime.context.db_connection
# 使用配置获取数据
results = perform_database_query(db_connection, query, api_key)
return f"Found {len(results)} results for user {user_id}"
agent = create_agent(
model="gpt-4o",
tools=[fetch_user_data],
context_schema=Context
)
# 使用运行时上下文调用
result = agent.invoke(
{"messages": [{"role": "user", "content": "Get my data"}]},
context=Context(
user_id="user_123",
api_key="sk-...",
db_connection="postgresql://..."
)
)写入(Writes)
工具结果可用于帮助 Agent 完成给定任务。工具可以直接向模型返回结果, 也可以更新 Agent 的记忆,使重要上下文可供未来步骤使用。
from langchain.tools import tool, ToolRuntime
from langchain.agents import create_agent
from langgraph.types import Command
@tool
def authenticate_user(
password: str,
runtime: ToolRuntime
) -> Command:
"""认证用户并更新 State"""
# 执行认证(简化)
if password == "correct":
# 写入 State:使用 Command 标记为已认证
return Command(
update={"authenticated": True},
)
else:
return Command(update={"authenticated": False})
agent = create_agent(
model="gpt-4o",
tools=[authenticate_user]
)from dataclasses import dataclass
from langchain.tools import tool, ToolRuntime
from langchain.agents import create_agent
from langgraph.store.memory import InMemoryStore
@dataclass
class Context:
user_id: str
@tool
def save_preference(
preference_key: str,
preference_value: str,
runtime: ToolRuntime[Context]
) -> str:
"""将用户偏好保存到 Store"""
user_id = runtime.context.user_id
# 读取现有偏好
store = runtime.store
existing_prefs = store.get(("preferences",), user_id)
# 与新偏好合并
prefs = existing_prefs.value if existing_prefs else {}
prefs[preference_key] = preference_value
# 写入 Store:保存更新的偏好
store.put(("preferences",), user_id, prefs)
return f"Saved preference: {preference_key} = {preference_value}"
agent = create_agent(
model="gpt-4o",
tools=[save_preference],
context_schema=Context,
store=InMemoryStore()
)生命周期上下文(Life-cycle Context)
控制核心 Agent 步骤之间发生的事情——拦截数据流以实现横切关注点, 如摘要、防护栏和日志记录。
如您在模型上下文和工具上下文中所见,中间件是使上下文工程变得实用的机制。 中间件允许您连接到 Agent 生命周期的任何步骤,并且:
- 更新上下文 - 修改状态和存储以持久化更改、更新对话历史或保存见解
- 在生命周期中跳转 - 根据上下文移动到 Agent 循环的不同步骤(例如,如果满足条件则跳过工具执行,使用修改的上下文重复模型调用)
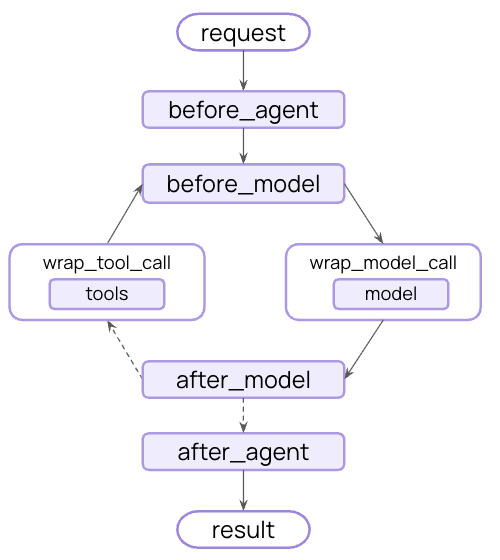
示例:摘要
最常见的生命周期模式之一是在对话历史过长时自动压缩它。 与模型上下文中显示的瞬态消息修剪不同,摘要持久地更新状态—— 永久地用摘要替换旧消息,该摘要将为所有未来轮次保存。
LangChain 为此提供了内置中间件:
from langchain.agents import create_agent
from langchain.agents.middleware import SummarizationMiddleware
agent = create_agent(
model="gpt-4o",
tools=[...],
middleware=[
SummarizationMiddleware(
model="gpt-4o-mini",
trigger={"tokens": 4000},
keep={"messages": 20},
),
],
)当对话超过 Token 限制时,SummarizationMiddleware 会自动:
- 使用单独的 LLM 调用摘要旧消息
- 在 State 中用摘要消息永久替换它们
- 保留最近的消息以提供上下文
摘要的对话历史会永久更新——未来的轮次将看到摘要而不是原始消息。
有关内置中间件的完整列表、可用钩子以及如何创建自定义中间件, 请参阅中间件文档。
最佳实践
- 从简单开始 - 从静态提示词和工具开始,仅在需要时添加动态性
- 逐步测试 - 一次添加一个上下文工程功能
- 监控性能 - 追踪模型调用、Token 使用和延迟
- 使用内置中间件 - 利用
SummarizationMiddleware、LLMToolSelectorMiddleware等 - 记录您的上下文策略 - 明确正在传递什么上下文以及为什么
- 理解瞬态 vs 持久:模型上下文更改是瞬态的(每次调用),而生命周期上下文更改持久到状态